Distributed Inference精读
这是一份针对论文《Galaxy: A Resource-Efficient Collaborative Edge AI System for In-situ Transformer Inference》 的精读笔记。
Abstract
Edge Computing
边缘任务,边缘计算等概念中的edge,指的是在用户或离数据源更近的设备上。主要是为了满足低延迟、减轻骨干网压力和保护隐私的作用(文章的下一句正是对后两个好处的提出)。 这篇文章的背景从Transformer-based models在edge场景的应用出发,提了voice assistant的例子。
In-site Inference
原地推理的意思,基本上是edge computing的一种转写,或者说是在edge和神经网络背景下的一种特化技术?
Edge Intelligence
应该是指AI在边缘场景中的表现。
核心问题是,“尽管有in-site inference的应用来解决边缘计算场景的方法,但它还是面临着解决workloads和liited resources的矛盾问题”
解决方案的基础是,注意到了有许多边缘场景下,存在很多trusted的edge device拥有idle resources,所以新的边缘AI系统,Galaxy,可以打破不同类型配置设备的resouces walls来加速transformer的inference。
实现上,Galaxy系统主要通过实现 hybrid model parallelism和heterogeneity-aware parallelism planning来使用资源。
Hybrid Model Parallelism
这指的是将模型的不同部分(例如层、张量等)划分并分配到多个边缘设备上并行计算。通过混合并行的方式,Galaxy 能够灵活地处理不同规模和复杂度的任务,使得多个设备可以在计算能力上进行合理分担,从而加速推理过程。
Heterogeneity-aware Parallelism Planning
由于边缘设备的硬件资源(如计算能力、内存、带宽等)不同,Galaxy 在进行任务分配时会考虑这些异构设备的具体特性。它能够根据每个设备的资源能力,智能地规划并行任务的分配,使得每个设备的资源得到最大化利用,同时避免过载和瓶颈。
Tile-based
这意味着将大规模的计算任务分割成较小的“瓦片”或片段,这样可以更细粒度地控制计算和数据传输。这种方式有助于在推理过程中充分利用设备的计算能力,并减少计算与通信之间的冲突。
Fine-grained
“细粒度”指的是在非常小的时间单位内进行重叠,而不是只在较大的数据块或计算任务完成后再进行同步。
Tensor Synchronizations ( on inference latency)
在多设备协同推理时,各设备需要同步张量(例如模型参数或计算结果)。这个过程如果不优化,会引入延迟。
Bandwidth-constrained
边缘设备通常受限于较低的网络带宽,尤其是在数据量大的时候,通信延迟会更显著。
评估上,本文使用了prototype implementation来做评估,达到了2.5x的端对端优化减少。
Prototype Implementation
指的是在目标平台(或近似平台)上,基于论文或设计思路快速开发出的一个“初步可用”系统版本。目的在于用真实代码跑通整个方案,并在实际或接近真实的环境中收集性能数据,验证设计的可行性与效果。其他AI领域常见的评估方法有
标准基准测试(Benchmarking)
- 利用公认的开源数据集和任务(如 ImageNet、GLUE、COCO、SQuAD、OpenAI Gym 等),在固定的评价指标(准确率、F1、BLEU、ROUGE、平均奖励、平均回报等)上做横向比较。
消融实验(Ablation Study)
- 系统地移除或替换模型中的某个模块/组件,观察性能波动,以量化各部分贡献。
性能剖析(Profiling)
- 利用工具(如 NVIDIA Nsight、PyTorch Profiler、TensorBoard)统计模型在不同硬件(CPU、GPU、TPU)上的延迟、吞吐量(throughput)、内存占用、能耗等。
模拟环境与仿真(Simulation)
- 对强化学习或多智能体系统,常用模拟平台(如 MuJoCo、CARLA、StarCraft II)来做大规模、可重复的性能评估。
State-of-the-art
“State-of-the-art” 是一个常用的术语,意思是当前领域内最先进、最顶尖的技术或方法。它代表了在某个特定时间点,经过研究和实践验证的最优方案。
End-to-end
“End-to‑end”直译是“端到端”,在 AI 与系统设计中,通常指从原始输入到最终输出整个流程都由一个统一的模型或系统自动完成,中间不依赖人工设定的特征提取或独立子模块。
Conclusion
结论部分基本是摘要部分的复写,去除了背景的介绍相关。 重点再次提及了 hybrid model parallelism, heterogeneity,memory-budget aware planning 的核心调度算法设计,和一个tile-based communication 优化的内容。并强调了表现上的2.5x的重大提升。 没有提及局限性和未来展望,可能不太好做后续工作?
Introduction
在边缘智能应用领域中,Transformer模型的实际推理通常在云端进行。而在边缘设备上,通常仅部署一个proxy daemon来转发用户请求。这种cloud-assisted的方法遇到了三个问题:
- 重视质量的服务可能遇到WAN链接不可靠和延迟问题
- 边缘设备的大量请求可能会对backbone network和数据中心施加巨大压力
- 在智能应用中的数据可能十分敏感,隐私问题。
为了解决这个问题,in-situ inference,即在边缘设备中无需远程协助进行推理,被视为未来的一种范式。然而Transformer推理具有computation-intensive 和resource-hungry的特征,即需要足量的数据和计算资源,是这种范式面临的主要挑战。在II-Bpart中,展示了一个Bert-L模型在普通边缘设备上的推理,需要700MB的内存,且延迟是数据中心GPU的121倍。目前的研究主要着重于设计复杂的调度制度来利用边缘设备的资源潜力,但仍然困扰于资源有限的问题。
这篇论文注意到了一点,像智能家居这样的普通边缘环境,往往包含一组闲置设备。这使得作者考虑将邻近的可用边缘设备视为一种资源扩展,并以分布式的方式进行协作,从而加速推理。但这种方法又带来了三种新的挑战:
- 如何将单次推理任务的Transformer工作负载在多个边缘设备之间进行并行化;
- 如何根据异构边缘设备的资源预算来决定工作负载的划分策略;
- 如何在带宽受限的边缘环境下减少分布式推理的延迟。
为了解决这些问题,Galaxy便是作者提出的一个collaborative edge AI system,实现了低延迟的Transfomer推理功能来支持in-situ 边缘智能设备。为了在最大化资源利用的同时协调异构辅助设备,提出了一种新的Hybrid Model Paralleism,它结合Tensor Parallelism和Sequence Parallelism的优点,作为一种新的并行架构来管理分布式推理工作流。其次,为了最大化资源使用,配备了一个workload planning 算法,该算法全面考虑了设备资源的resource heterogeneity和memory budget。第三,为了在带宽受限的环境下实现低延迟,通过连续计算和通信操作解耦,并分解为fine-grained tiles,从而实现高效的同步重叠。实验表明,与单一设备情况相比,Galaxy的4路并行方法能够打到86%的扩展效率,实现了最高2.5倍延迟的加速。且这是首个将HMP应用在边缘协同Transfomer推理场景的研究。
总的来说,这篇论文主要实现了以下贡献:
通过对设备本地(on-device)和并行推理方法进行广泛的测量研究,我们引入了一种新颖的混合模型并行性(Hybrid Model Parallelism,HMP)架构,以与受信任的边缘设备协作,实现原位单次(single-shot)Transformer推理加速。
我们设计了一种考虑异构性(heterogeneity)和内存预算(memory-budget)的工作负载规划算法,以促进资源高效的边缘协同推理。
我们提出了一种基于瓦片(tile-based)的细粒度优化,利用通信与计算重叠(communication and computation overlapping)概念来缓解同步开销。
我们实现了Galaxy系统,并在真实的边缘测试平台上进行了评估。实验结果表明,相较于最先进的方法,延迟最多降低了2.5×。
相关工作和研究起点
Transformer层的组成与工作原理
当前和语言相关的应用都趋于使用Transformer的模型。Transformer主要多个Transformer层堆叠而成。原始模型包括Encoder和Decoder各一个,这篇论文主要集中于Bert(只用了编码器,着重理解)和GPT-2(只用了解码器,强调生成)。
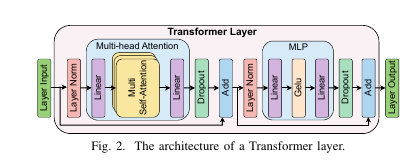
在一个Transformer层中,主要组件有MHA块和MLP快。这些组件通过element-wise的操作,例如Dropout,Residual Addition,LayerNorm,来连接。
在MHA模块中,第一层线性变换分别生成每个注意力头的查询(Q)、键(K)和值(V)矩阵。每个注意力头独立执行自注意力(self-attention)计算,之后将各头的输出拼接(concatenate),再通过一层线性变换,得到最终输出。
MLP模块则包含两次线性变换:第一次将隐藏维度从 h 提升到 4h,第二次再将其降回h。
多头自注意力(Multi-head Attention, MHA)
输入:将上一层(或输入嵌入)得到的向量序列,先通过三个独立的全连接(linear)层,分别生成
Query (Q) 矩阵
Key (K) 矩阵
Value (V) 矩阵
操作:对每一个“头”(head)独立地计算自注意力:
\[\text{Attention}(Q,K,V) = \text{softmax}\bigl(\tfrac{QK^T}{\sqrt{d_k}}\bigr)V\]多头并行:将多个头的输出拼接(concatenate),再通过一个全连接层得到最终的 MHA 输出。
作用:让模型能够“关注”输入序列中任意两个位置之间的依赖关系。
前馈网络(Multilayer Perceptron, MLP)
包含两次线性变换:
将维度从 h 扩大到 4h
再从 4h 缩回到 h
中间通常会加上非线性激活(如 GELU)
作用:为每个位置的向量提供更丰富的特征变换。
层内连接与正则化
残差连接(Residual Addition):在 MHA 和 MLP 前后,都有一条跨层的“捷径”相加,帮助梯度更稳定地流动。
层归一化(Layer Norm):在残差相加后,对每个位置的向量进行归一化,提升训练收敛速度与稳定性。
Dropout:在训练时随机丢弃一部分神经元连接,防止过拟合。
Encoder vs. Decoder
原始 Transformer 同时包含 Encoder(只用自注意力)和 Decoder(在自注意力基础上再加一个“对 Encoder 输出的注意力”)。
BERT 只使用 Encoder;GPT-2 只使用 Decoder,本文关注的就是这两类“单边”结构。
在资源受限的边缘设备上进行 Transformer 推理
实验了不同模型在边缘设备上运行的表现,如表1
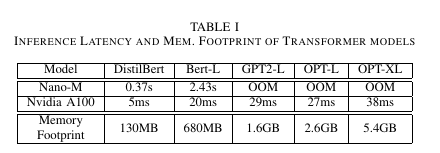
可以看到,在Nano-M上的运行表现往往有100多倍延迟,且还有内存预算受限的问题,例如GPT2-L需要1.6GB,大于Nano-M的1.5GB预算。为了解决这一点,论文作者利用多台物理上相接近的设备来实现计算资源共享。
多设备协同Transformer推理
有两种并行方案如下
Data 和 Pipeline 并行
数据并行性(DP)和流水线并行性(PP)是常见的并行计算方式,广泛应用于 Transformer 模型的并行执行。
- 数据并行性(DP):沿着样本维度划分工作负载,使每个设备独立进行推理。在边缘智能服务中,常常会有单次推理请求(例如向智能助手发送单一语音命令),此时由于没有数据批次,数据并行性不适用。
在传统的大规模训练中,数据并行性非常有效,因为可以通过复制模型参数到不同的设备上,让每个设备计算自己的梯度,并最终合并梯度进行更新。
- 流水线并行性(PP):将模型沿着层维度水平划分为多个连续阶段,每个阶段分配到不同设备上进行处理。然而,在单次推理的情况下,由于阶段间的数据依赖性,流水线并行性无法有效利用多个设备并行工作,因为每个设备必须等待前一个设备的完成才能继续。
Model 并行
模型并行性(MP) 是一种并行计算范式,它沿着模型层内的操作将任务水平划分,从而实现单次推理的并发执行。应用于 Transformer模型的最常见模型并行技术包括 张量并行性(Tensor Parallelism, TP)和序列并行性(Sequence Parallelism, SP)。
张量并行性(TP):将模型的权重划分到不同设备上,每个设备保存一部分参数。然而,TP 无法并行化 MHA 和 MLP 模块之间的一些按元素计算操作。
序列并行性(SP):沿着序列维度划分输入数据,便于对所有操作进行并行计算,但需要每个设备存储完整的模型参数。
由于层内数据依赖性,在模型并行性中需要插入同步点以确保协同推理和本地推理结果的一致性。然而,这些同步点会引入显著的通信延迟,尤其在带宽受限的边缘环境下,可能成为推理性能的瓶颈。 于是作者设计了混合模型并行架构(Hybrid Model Parallelism, HMP),它结合了 TP 和 SP 的优点,并采用通信优化方法以减轻同步开销。
数据并行性(Data Parallelism) 是在数据中心中最广泛使用的分布式训练方法。为了解决大规模 Transformer 模型训练中的内存问题,提出了流水线并行性(Pipeline Parallelism),但它容易受到流水线气泡(pipeline bubbles)影响。模型并行性(Model Parallelism) 同时解决了内存问题和气泡问题,广泛应用于数据中心的训练和推理任务。然而,这些方法很少针对边缘设备上的原位深度学习进行设计。
In-situ DNN 推理
Pipe-It 和 Asymo 根据不对称的移动 CPU 核心的计算能力调度工作负载,以实现更高的吞吐量。BlastNet、CoDL 和 μlayer 同时在移动 CPU 和 GPU 上执行协同 DNN 推理。Band 协调异构移动处理器上的多 DNN 推理。CoEdge、DeepThings 和 DeCNN 将 CNN 推理工作负载分配到多个资源受限的边缘设备上。然而,这些方法很少针对基于 Transformer 的模型进行设计。
- Pipe-It:一种调度策略,它通过将卷积层划分并限制每个核心集群内的并行化,减少了跨集群的通信开销,从而提高了推理吞吐量。该框架利用卷积层描述符预测每层在不同核心配置下的执行时间,并使用高效的设计空间探索算法创建平衡的流水线。
- Asymo:在 Pipe-It 的基础上,进一步提升了在不对称移动 CPU 核心上的推理效率,采用了线程池实现,解决了性能扩展性差的问题。
- BlastNet 是一个支持跨处理器实时 DNN 推理的系统。它引入了“Duo-Block”模型推理抽象,支持在 CPU 和 GPU 之间高效地调度和执行 DNN 推理任务。该系统通过优化模型分块和调度策略,实现了在异构处理器上的高效推理 。
- CoEdge 是一个分布式 DNN 计算系统,旨在协调异构边缘设备上的协同推理。它动态地将 DNN 推理工作负载划分到多个设备上,考虑设备的计算能力和网络状况,以最小化系统能耗并满足响应延迟要求。
- DeepThings 是一个针对资源受限的 IoT 边缘集群的分布式自适应 CNN 推理框架。它通过局部分布式和自适应的推理方式,优化了 CNN 模型在边缘设备上的执行效率。该框架考虑了设备的资源限制,动态地调整推理任务的分配,以提高整体性能 。
- DeCNN 是一种更有效的推理方法,采用解耦的 CNN 结构来优化模型并行性,以适应分布式推理。通过将 CNN 模型的不同部分分配到不同的设备上,DeCNN 实现了更高效的推理过程,特别是在边缘设备上 。
- Band 是一个高效的深度学习平台,支持多 DNN 工作负载在异构处理器上的协同推理。它通过协调不同 DNN 请求的执行,优化了移动设备上多 DNN 推理的性能。该平台支持后端无关的 DNN 请求协调,适用于多种硬件平台 。
分布式深度学习的通信优化
ZeRO++ 利用量化通信减少通信开销。Hermes采用模型结构修剪(model-structured pruning)来减少通信量。CoCoNet 和 ASE采用计算-通信重叠的概念,减轻通信延迟。然而,这些方法很少专门致力于基于 Transformer 的模型的模型并行性优化。
- ZeRO++ 是 DeepSpeed 提出的优化方案,通过量化权重和梯度,并对模型进行分层分区,显著减少大规模模型训练中的通信数据量,从而提升训练效率。
- Hermes 是一个针对联邦学习的通信优化框架,使用个性化稀疏网络和动态数据集分配方法,减少设备间的通信量并提高模型性能。
- CoCoNet 是一个分布式机器学习优化工具,利用领域特定语言和编译器,融合计算和通信优化,显著提升深度学习系统的性能。
- ASE 是一个自适应通信优化框架,通过重叠通信与计算、动态调整更新频率,以及优化异构资源环境中的通信策略,提高分布式训练的效率。
Methods
Workflow
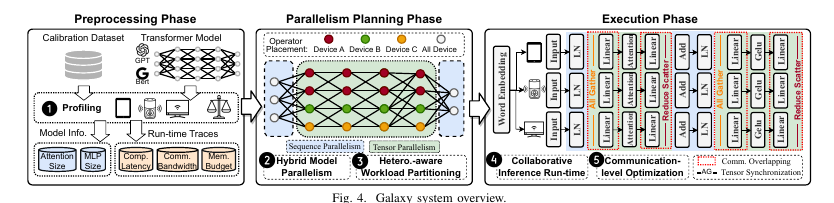
它包括三个主要阶段:预处理阶段、并行规划阶段 和 执行阶段。
- 预处理阶段:这是一个离线过程,在部署之前运行一次。Galaxy Profiler 使用校准数据作为输入,在物理边缘设备上执行推理过程,记录并行规划所需的运行时信息(步骤 1)。
- 并行规划阶段:Galaxy 采用一种新颖的混合模型并行架构(HMP),结合了 张量并行性(TP) 和 序列并行性(SP),来协调分布式边缘设备(步骤 2)。
Galaxy Planner 将 Galaxy Profiler 的分析结果作为输入,生成并行规划配置(步骤 3)。这个配置全面考虑了设备的资源异质性和内存预算,随后在 执行阶段 被应用到目标模型和边缘设备上,以实现高效的边缘协同推理(步骤 4)。 - 执行阶段:分布式推理不可避免地涉及张量同步操作。Galaxy 引入了基于瓦片的细粒度通信优化,以减少由额外通信开销带来的性能下降(步骤 5)。
Hybrid Model Parallelism
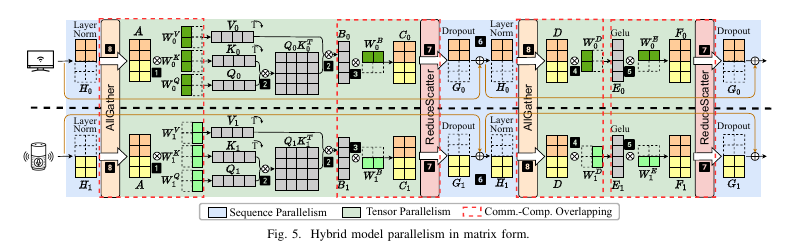
TP和SP被交替应用在Transformer层。具体来说,TP被应用于MHA和MLP模块,而SP被应用在连接MHA和MLP模块之间的操作,称为连接模块。
MHA模块中的TP
设计一个高效的 TP(张量并行性) 方法的目标是减少跨设备分割的操作之间的数据依赖关系,从而减少张量同步的频率。在MHA模块中,多个注意力头的计算本身是完全独立的,故可以不进行张量同步打到前提下,将每个头分配到不同的边缘设备上计算。基于这一点,将KQV权重矩阵,沿着头维度进行划分。具体步骤如下:
- 初始的GEMM矩阵被分配到不同的设备,并沿着头维度进行并行化
- 每个注意力头的自注意力操作在格子的设备上本地执行
- 从输出线性层得到的GEMM被沿着其行维度并行化,确保与初始的GEMM的头级划分对齐。
MLP模块中的TP
在MLP模块中,包含了两个连续的GEMM操作,为了避免第一个和第二个操作之间的张量同步,利用了MAtrix Tiling的概念来消除数据依赖拐西。步骤如下:
- 将第一个GEMM的权重矩阵沿其列维度进行划分
- 将第二个GEMM沿着行维度进行划分,以与第一个GEMM的列划分对齐
这样的操作下,第二个GEMM可以直接使用第一个GEMM的输出作为输入,而不需要同步。
连接模块中的序列并行性
TP 加速了每个 Transformer 层中最具计算密集度的部分,而对于连接 MHA 模块 和 MLP 模块 的 Dropout、残差相加(Residual Addition) 和 层归一化(Layer Norm) 等操作,则保持不变(步骤 6)。虽然这些操作是按元素计算的,不涉及大规模的矩阵乘法,但它们需要大量的内存访问,因此也会带来一定的执行延迟。我们注意到,这些按元素操作在序列维度上是独立的,这使得我们可以通过划分输入序列来对它们进行并行化。
张量同步点
在每个 TP 和 SP 模块的末尾需要设置一个同步点。 在 TP 模块完成时,需要执行 ReduceSum 操作,以聚合多个设备之间的计算结果。接着,聚合后的结果会沿着序列维度进行划分,并分发到多个边缘设备上进行 SP 计算。这两个操作可以通过一个 ReduceScatter 操作高效地结合并实现(步骤 7)。 在 SP 模块完成时,每个设备仅保留输入序列的一部分。此时,需要将所有这些片段收集、拼接,并将它们分发到所有设备上,以便进行后续的 TP 计算。因此,在每个 SP 模块结束时,我们执行一个 AllGather 通信原语
ReduceSum是一种将多个节点上的数据进行求和的操作,通常用于将每个设备计算的梯度汇总到一个指定的根节点(root)。ReduceScatter是一种将多个节点的数据进行归约后,结果均匀地分散到所有节点上的操作。AllGather是一种多对多的通信操作,它将每个节点上的数据收集到所有节点上。具体而言,每个节点将其本地的数据发送给其他所有节点,并接收来自其他节点的数据。最终,每个节点都会拥有来自所有节点的数据副本。知乎专栏(可以进一步学习DeepSpeed)
混合模型并行架构(HMP 架构)的优点
与 TP 相比:
- HMP 架构 消除了连接模块中的冗余计算,充分挖掘了 Transformer 层的并行潜力。
- HMP 不会引入额外的通信开销。乍一看,最先进的 TP 方法需要进行两次 AllReduce 操作,而 HMP 每个 Transformer 层只需要执行两次 ReduceScatter 和两次 AllGather 操作。然而,在通信原语的实现中,一次 Ring-AllReduce 操作的通信量相当于一次 Ring-ReduceScatter 后接一次 Ring-AllGather。
- HMP 架构 将一个较大的 AllReduce 操作拆分成两个更小的原语,ReduceScatter 和 AllGather,这大大促进了我们在 §III-D 中提出的基于瓦片的通信重叠。
与 SP 相比:
SP 沿着序列维度对输入张量进行划分,而不对权重矩阵进行划分。这种范式要求每个设备存储整个全局模型的副本。HMP 通过将模型参数分布到多个设备上,解决了这一问题,打破了单一设备的内存壁垒,并实现了内存资源的可扩展性。
考虑异构性和内存的工作负载规划算法
问题阐释
在每个 TP 或 SP 模块完成后,需要设置同步点。这些同步点的启动受到最慢设备(straggler)完成时间的限制。此外,基于 Transformer 的模型推理需要大量内存。在实际部署中,内存溢出(OOM)问题是推理过程中的“致命问题”,因此还需要考虑每个设备的内存预算。
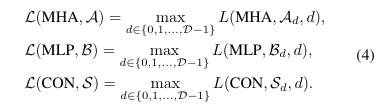
上述公式是用于最小化执行延迟的目标函数。,出了最小化执行延迟外,还需要防止OOM问题,内存占用问题主要来自MHA和MLP模块的庞大权重矩阵。因此,需要主要考虑这两个内容的工作划分。将这些因素结合起来,最小化延迟的优化目标在内存约束下为:
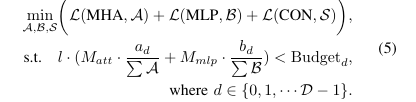
为此,设计了Galaxy Profiler,它通过使用标定数据集作为输入在物理边缘设备上执行推理过程,记录并行规划所需的运行时信息。同时,Galaxy Profiler 还记录了模型的信息,包括 MHA 和 MLP 模块中包含的参数数量。
算法实现

连接模块 的执行时间主要依赖于内存访问量,而非 SoC(系统级芯片)的计算能力。而SP的部分,采用了均匀划分策略,它可以保证在张量同步期间,所有设备的通信量相对均衡,也位之后的通信重叠奠定了基础。对于TP的部分,根据每个设备的计算能力实现快的最优划分,而不考虑内存预算。这种比例划分,能确保所有设备几乎同时完成任务。 因此设计了一个两步启发式算法。在第一步中,算法忽略设备的内存约束,按照设备的计算能力分配工作负载,从而确保工作负载的均衡。随后,在此初步分配的基础上,第二步进行微调。它将超出内存预算的设备的多余工作负载重新分配给有剩余内存的设备。考虑到 MHA 模块(头维度)的划分粒度通常比 MLP 模块(列维度)粗,我们首先重新分配 MLP 模块的工作负载,然后是 MHA 模块。如果在重新分配工作负载后仍然出现 OOM 错误,表明参与协同推理的边缘设备无法容纳目标模型,从而导致算法失败。 这个算法将在部署之前运行一次,它的算法上界为O(D3)。在实验中,算法的运行时间不到1秒。
通信优化
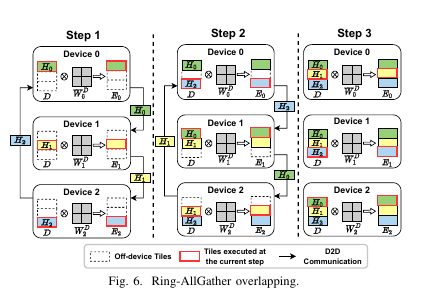
与数据中心中稳定且高带宽的网络不同,边缘环境经常面临不稳定且带宽受限的连接问题。 计算和通信重叠是一种有效的优化策略。然而,由于计算和通信之间严格的数据依赖关系,在 Transformer 推理中实现这一策略变得十分复杂。从 图 5 中可以看出,每个 TP 模块以 GEMM 操作开始并结束。我们设计了将这些 GEMM 操作与进入和退出 TP 模块时的 AllGather 和 ReduceScatter 操作重叠的策略。为了说明这一点,接下来的部分提供了一个跨三个设备的协同推理示例,展示了如何在 MLP 模块之前和之后的同步点与 GEMM 操作重叠(同样适用于 MHA 模块)。
ALLGather重叠
如 图 5 所示,AllGather 和 MLP 模块中的初始矩阵乘法(GEMM1) 之间存在严格的数据依赖关系。具体而言,设备 i(i ∈ {0, 1, 2})上的 GEMM1 只能在 AllGather 完成所有子序列的聚合后开始执行。为了消解 AllGather 和 GEMM1 之间的严格依赖关系,我们利用 矩阵瓦片化 方法对 GEMM1 进行分解。我们发现,直接计算 GEMM1 可以通过将矩阵 D 水平划分为多个瓦片,在每个瓦片上独立执行 GEMM1,然后将结果拼接起来,从而等效地实现计算。
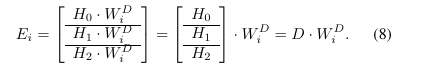
ReduceScatter重叠
MLP 模块 中的最终矩阵乘法(GEMM2)与 ReduceScatter 操作之间存在严格的数据依赖关系。为了消解 ReduceScatter 和 GEMM2 之间的严格依赖关系,我们采用与 AllGather 操作类似的 矩阵瓦片化 方法。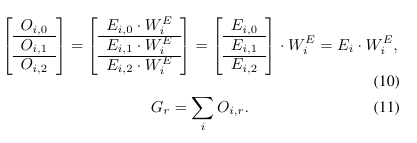
了得到最终结果 Gr,还需要在所有设备上执行一次 ReduceSum 操作(公式 11)
- Ring-ReduceScatter 是 ReduceScatter 的一种实现方法,它使用 环形拓扑 来组织设备之间的通信。环形拓扑是指设备按照一个环形结构连接,每个设备仅与前一个设备和后一个设备相连。
实验
模型和数据集
我们使用五个典型的 基于 Transformer 的模型 来评估 Galaxy,这些模型的参数数量从 6600 万到 27 亿不等,从流行的 GLUE 数据集中提取了一个子集,其中平均序列长度为 284,用于评估。
边缘环境设置
在多种现实边缘环境中评估 Galaxy,包括异构和同质的现成边缘设备配置。仅使用板载 CPU 来模拟资源受限的边缘场景。
基准方法
我们将 Galaxy 与以下两种基准方法进行比较:
- 本地推理(Local):在单台设备上推理模型。我们与其比较,分析 Galaxy 的扩展性性能。
- Megatron-LM (M-LM) [24]:一种最先进的 TP 方法,将 MHA 和 MLP 模块中的权重矩阵进行拆分,以并行化 GEMM 操作。每个 MHA 和 MLP 模块之后需要执行一次 AllReduce 同步。
- 序列并行(SP) [25]:一种最先进的 SP 方法,通过沿序列维度划分输入并在多个工作设备上并行推理。每个 MHA 模块需要进行两次 AllGather 同步。
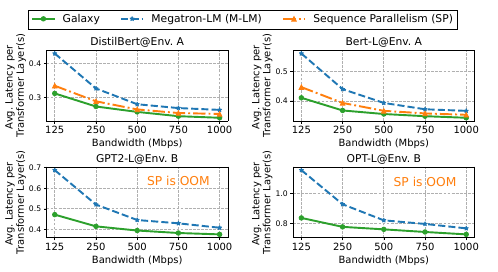
与 M-LM 相比,Galaxy 提高了多达 1.46倍 的性能。随着模型大小的增加,通信与计算的比例下降,从而缩小了我们的通信优化空间,导致加速比下降。
与 SP 相比,Galaxy 提高了 1.11倍 的性能提升。SP 需要的同步通信较少,导致加速比较小。然而,SP 沿序列维度划分输入,需要每个设备保持完整的模型权重副本,这对于内存受限的边缘设备来说非常不友好,容易导致 OOM 错误。
在多个异构边缘环境中对 Galaxy 与基准方法进行比较(带宽为 125Mbps),每个环境包含不同计算能力和内存预算的设备。结果如 图 9 所示。我们观察到,Galaxy 在各种异构边缘环境中始终显著优于其他最先进的并行方法,推理延迟减少的幅度在 1.3× 到 2.5× 之间。Galaxy 在异构环境中的优越性能来源于其考虑了设备的异构性,而 M-LM 和 SP 都忽略了这一因素,它们主要面向具备同质加速器的数据中心。

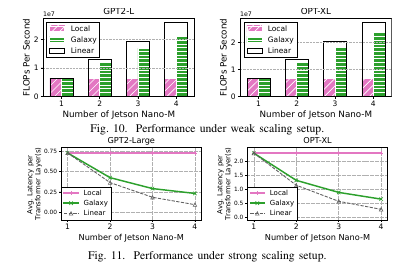
为了探索 Galaxy 的可扩展性,我们在边缘环境 C(1000Mbps)中设置了弱扩展和强扩展实验。为了消除 OOM 错误对实验结果的影响,我们加载并反复执行单个层的推理,而不是加载整个模型。
弱扩展(Weak Scaling):在弱扩展设置中,随着设备数量的增加,全局工作负载按比例增加。我们设置了一个固定序列长度为每个设备 96(例如,4 个 Jetson Nano-M 时序列长度为 384)。然后评估整个系统的浮点运算每秒(FLOPS)。如 图 10 所示,我们观察到在 GPT2-L 和 OPT-XL 的实验中,扩展性能非常好。特别是在 GPT2-L 的 4 台设备(四个 Jetson Nano-M)情况下,HMP 达到了 81% 的线性扩展;而在 OPT-XL 4 台设备的情况下,达到了 86% 的线性扩展。
强扩展(Strong Scaling):在强扩展设置中,全局工作负载与参与设备数量无关。我们固定序列长度为 384。如 图 11 所示,我们测量了每个 Transformer 层的平均推理延迟,并在不同数量的边缘设备上进行实验。Galaxy 在强扩展设置下也展示了出色的可扩展性。特别是,在 GPT2-L 实验中,Galaxy 比 Local Inference 提高了 3.05× 的推理延迟;而在 OPT-XL 实验中,Galaxy 比 Local Inference 提高了 3.24× 的推理延迟。
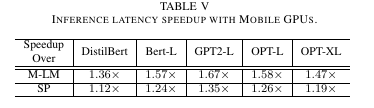
我们进一步在移动 GPU 环境中评估了 Galaxy 的性能,并与基准方法进行了比较。GPU 环境设置使用了两台 Jetson Nano 的板载 GPU,频率锁定为 460MHz。实验涵盖了所有五个 Transformer 模型,并使用边缘环境 A(500Mbps)。结果如 表 V 所示。我们观察到,在 GPU 环境中,Galaxy 优于基准方法,实现了 1.12×-1.67× 的推理延迟减少。尽管对于像 DistilBERT 这样的小模型,由于 Galaxy 的通信优化与矩阵瓦片化,可能会导致 GPU 未得到充分利用,但 Galaxy 相比基准方法仍然实现了最高 1.36× 的加速。
相关内容的下一步阅读
Reducing Activation Recomputation in Large Transformer Models ,和这篇文章的MHA框架设计相似。 # 关于Deepspeed的一些总结与心得,了解分布式深度学习的相关内容
参考了学习笔记Galaxy: A Resource-Efficient Collaborative Edge AI System for In-situ Transformer Inference - 知乎完成